РАСПОЗНАВАНИЕ ОБРАЗОВ
Содержание:
- Text Fairy
- Принцип действия
- Программы
- Веб-приложение Free-OCR
- Применение алгоритмов обучения распознаванию образов
- Microsoft Office Lens
- Вытаскиваем текст с картинок и PDF
- OCRONLINE
- NEWOCR.COM
- Суть процедуры
- Особенности
- Текущее состояние технологии оптического распознавания текста
- Краткое описание плагина Copyfish
- Преобразование графического файла
- Onlineocr.net
- Онлайн-сервисы
- Применение методов распознавания образов в медицине
Text Fairy
Комбинации клавиш в Ворде: Все главные сочетания для работы

№10. Text Fairy
«Текстовая Фея» (а именно так переводится название) – это приложение для платформы Android, которое может распознавать текст на изображении (при использовании камеры) и перевести его. Теоретически. В реальности все не так радужно.
В принципе, Text Fairy справляется со своей работой. Но очень топорно. К примеру, бывает так, что программа вроде бы распознала текст, вроде бы даже сохранила его в формате PDF. Открываешь файл – а там значки и цифры. Ну и как это называется?
О переводе и вовсе нечего говорить. Даже туповатый Magic Gooddy (если кто помнит такой переводчик из начала 2000-х) и то получше справлялся со своей работой. А здесь – тупой машинный текст.
Венцом всему – непродуманный, страшный интерфейс. Да еще и без русского языка. Неизвестно, на кого рассчитано это приложение, но работать с ним – то еще испытание. Некоторые, правда, умудряются.
Преимущества:
- приложение совершенно бесплатно
- очень быстро работает (если работает)
- умеет переводить (почти)
- малый размер приложения
Недостатки:
- не всегда адекватно сохраняет результат
- нет русского языка
- обилие рекламного контента
Принцип действия
Как же работает такая программа? Какие алгоритмы используются для распознавания текста и как они взаимодействуют в софте? Чем объясняются отличия в качестве распознавания материалов разными программами?
Принцип действия программы такой:
1 В каждой программе имеется база данных, в которую занесен алфавит, при этом каждой букве, как строчной, так и заглавной, присваивается целая группа вероятных графических отображений этой буквы – различные шрифты, учет качества фото, поворота и угла камеры при съемке и т. д.;
2 Таким образом, после попадания в программу изображение анализируется с целью выявления имеющихся символов и определения их положения, то есть, фактически, определяется, где именно на фото расположены буквы;
3 Распознавание обнаруженных букв, по окончанию которого формируется печатный текст;
4 Распознавание особенностей форматирования, величины отступов и т. д. (только некоторые программы способны сохранять форматирование, при работе большинства доступных бесплатных сервисов этот пункт вовсе отсутствует);
5 Как только распознавание заканчивается, то, в зависимости от типа программы и принципов ее работы, готовый текст появляется в окне софта или создается текстовый файл с ним (того или иного формата, также в зависимости от программы).
Полученный таким образом материал остается только отредактировать.

Программы
Какие же программы используются для распознавания?
Они делятся на две группы: платные и бесплатные установочные программы, платные и бесплатные мобильные утилиты.
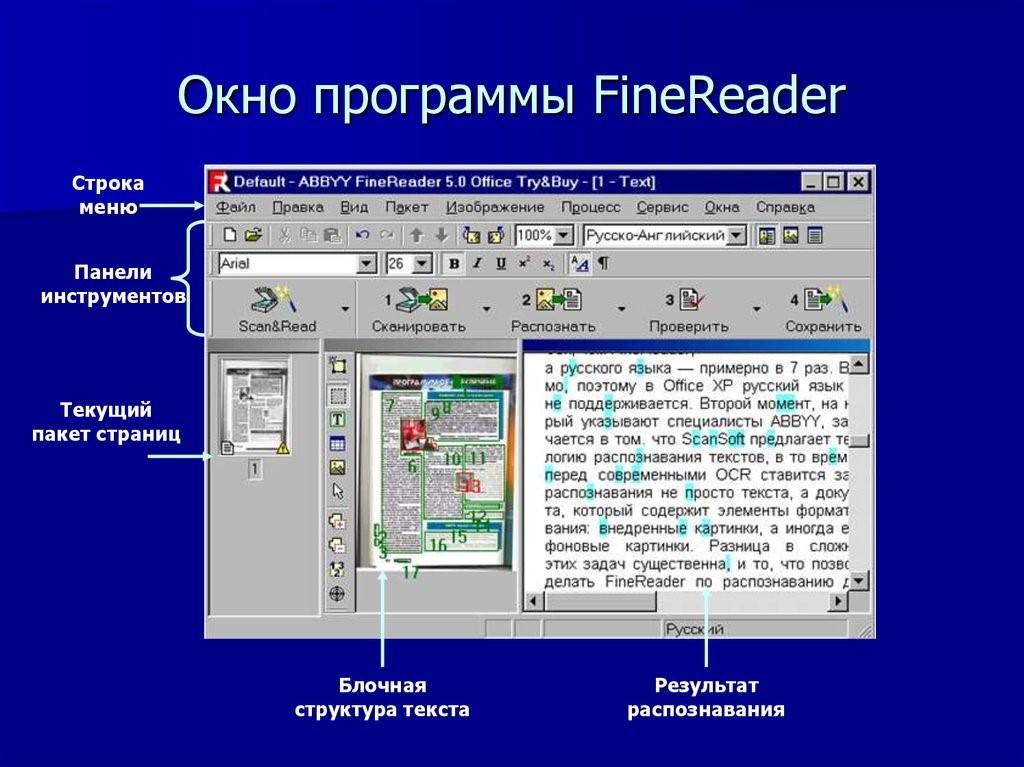
Требующие установки
Такой софт подойдет тем, кто постоянно работает с изображениями с текстом.
Кроме того, такой софт, обычно, наиболее функциональный.
| Программа | Тип лицензии | Функционал | Особенности | Рейтинг |
|---|---|---|---|---|
| Платно | Полный | Подходит для профессионального распознавания текста | 4,0 | |
| Бесплатно | Суженный | Неплохой функционал, но меньший, чем в платных аналогах | 2,9 | |
| Платно | Расширенный | Программа предназначена для выполнения широкого спектра работ с файлами PDF, в том числе и с распознаванием текста со сканов | 3,4 | |
| Платно | Более узкий, по сравнению с другими платными аналогами | Довольно неудобное меню и управление, из-за которого программа не пользуется популярностью | 3,0 |
Очевидно, что выбор подходящего софта зависит от того, какие требования к нему предъявляет пользователь. Однако, в большинстве случаев, непрофессионалы вполне могут обойтись бесплатными программами для периодического использования.
Веб-приложение Free-OCR
Главное преимущество данного сервиса – возможность работы практически со всеми форматами картинок.
К примеру, большинство сервисов распознавания текста не поддерживают такие форматы, как gif, bmp или tif.
Внешний вид сайта очень простой, таким образом каждый пользователь сможет справиться с поставленной задачей.
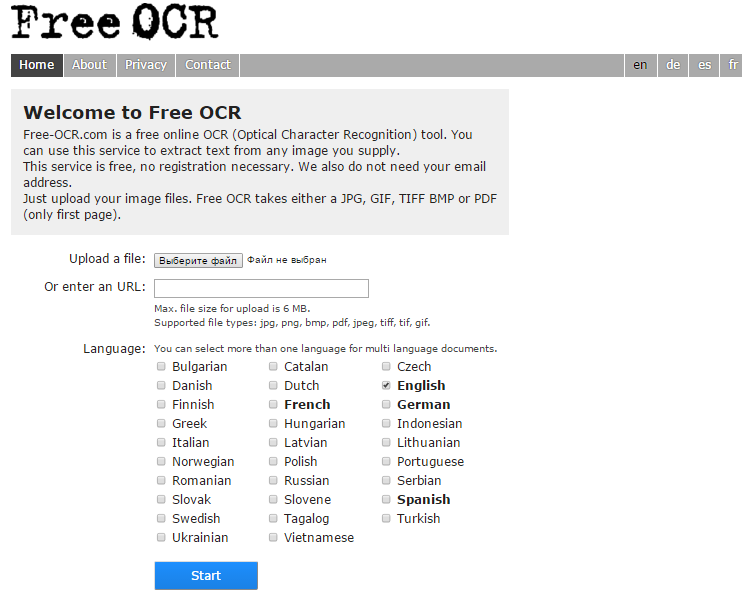
Внешний вид веб-приложения
Удобнее всего переводить текст в Word, ведь данная программа способна отобразить огромное количество различных текстовых кодировок, а также элементы дизайна входящего файла.
Данный сервис является абсолютно бесплатным и не требует пользовательской регистрации.
Единственное ограничение — размер входящего файла должен быть меньше, чем 6 мегабайт, поэтому распознавать большие документы с помощью данной программы не получиться.
Самое точное направление распознавания – с формата JPEG в ворд.
Тематические видеоролики:
Онлайн распознавание текста — ТОП-3 сервиса
Онлайн распознавание текста — ТОП-3 сервиса
Как распознать текст с картинки онлайн — Google Диск
Как распознать текст с картинки, фотографии или PDF документа онлайн, бесплатно с помощью Google Диска или Документов Гугл
8 Рейтинг
Краткий обзор
Весьма простые сервисы для онлайн-распознавания текста с изображений. На их освоение даже не нужно время, ведь там все элементарно и просто. Огромным плюсом является отсутствие необходимости вкладывать в работу с этими сервисами деньги.
Сложность использования
7
Время на освоение
7
Стоимость
10
Применение алгоритмов обучения распознаванию образов
Выделяют два типа задач Р. о.: задачи, связанные с классификацией естественной для человека информации, т. е. такой информации, к-рая возникала в процессе его фило- и онтогенеза (напр., классификация зрительных образов, классификация звуков речи и т. д.); задачи, связанные с классификацией не естественной для человека информации, т. е. не встречавшейся в фило- и онтогенезе (напр., задачи технической и медицинской диагностики, задачи прогнозирования и т. п.).
Для решения задач первого типа пока не удается построить устройство, работающее с той же точностью, что и человек, тогда как при решении задач второго типа технические устройства, как правило, проводят классификацию точнее человека.
Работы по внедрению методов Р. о. ведутся для обоих типов задач. Так, на принципе Р. о., связанных с классификацией естественной для человека информации, разрабатываются устройства автоматического чтения печатного и машинописного текстов, что позволяет непосредственно вводить документы в ЭВМ. Разработаны читающие автоматы. Ведутся работы по созданию устройств для подачи ЭВМ команды голосом, обмена с нею информацией голосом (автоматический синтезатор звуков речи уже создан), построения автоматического стенографического устройства и т. д.
Созданы устройства, способные различать до 100 слов, что достаточно, чтобы задавать машине голосом программу действий.
Еще более успешно применяются методы Р. о. для решения задач второго типа (т. е. классификация не естественной для человека информации). Так, методы распознавания широко используются в геологии при принятии решений о наличии полезных ископаемых по результатам комплексного обследования региона (напр., при поиске нефти распознавание нефтеносных пластов), в метеорологии при составлении по синоптической информации прогнозов гололеда, шквалов, заморозков и т. д. Имеется опыт применения методов Р. о. для организации неразрушающего контроля качества продукции. Так, по особенностям работы электронных приборов в различных режимах судят об их долговечности.
Microsoft Office Lens
Как изменить формат фотографии: Подробные инструкции к нескольким редакторам


№8. Microsoft Office Lens — PDF Scanner
А это уже приложение для смартфона, которое умеет распознавать текст с использованием камеры аппарата. Задумка, конечно, хороша, но было бы гораздо лучше, если б разработкой этой программы не занималась компания Microsoft.
Детище Билла Гейтса имеет уникальную «суперспособность» – портить все, к чему прикасается. И в этом приложении авторы незабвенной Windows 10 остались верны традициям. Приложение работает из рук вон плохо: частые вылеты, фризы и глюки.
Что до качества распознавания текста, то оно ужасно. Приложение справляется со своими функциями через раз. А иногда такого увидит в изображении, что глаза начинают кровоточить. Тем не менее, иногда программа работает четко. Неизвестно, от чего это зависит.
Особенно раздражает постоянные предложения поделиться распознанным текстом и воспользоваться для этого туповатым облачным сервисом OneDrive. А от обилия рекламы и вовсе в глазах рябит. Что же делать – бесплатное приложение.
Преимущества:
- неплохая задумка
- приложение совершенно бесплатно
- неплохая работа с камерой устройства
- русский язык в интерфейсе
- иногда программа даже распознает текст
Недостатки:
- отвратительная оптимизация приложения
- постоянные глюки, фризы и вылеты
- нереальное количество рекламы
- выводящее из себя предложение воспользоваться OneDrive
- программа распознает текст через раз
Вытаскиваем текст с картинок и PDF
Независимо от того, с какого источника вам требуется выделить текст, ниже представленные сервисы помогут это сделать.
Например, вы можете создать вот такую картинку:

Это часть текста с нашего блога, почитайте статью «Удобная работа со скриншотами», если не знаете, как сделать такое изображение. Готовую картинку нужно загружать на специальные сайты и запускать обработку:
1. – когда перейдете на сайт, воспользуйтесь формой загрузки, где можно добавить файл с компьютера или просто указать ссылку на него. Сначала нажимаете Preview, потом выбираете язык для преобразования текста и нажимаете кнопку OCR. Через несколько секунд вы получите результат.
2. – аналогичный сервис, где сразу выбирается файл, язык и формат получаемого текста. У этого сайта есть минус, он не всегда работает из-за перегрузки. Исходник может быть в формате PNG, JPEG и PDF. После обработки дают ссылку для скачивания txt файла с результатом.

3. – подойдет система только для распознавания текста онлайн с картинок (PDF не поддерживается). Практически любой формат изображения можно загрузить и пройдя 3 простых шага, получить результат. Просто выбираете язык, загружаете файл или даете ссылку на него, вводите капчу и запускаете обработку.
4. – в отличие от аналогов, в этой системе можно получить результат в формате Word. За час можно обрабатывать не более 15 файлов, а максимальный размер картинки 5 Мб. Интерфейс тоже предельно простой, выбирается файл, язык и получаемый формат, после чего он конвертируется.

5. – последний качественный инструмент для распознавания текста с фото онлайн. Допускаются все популярные форматы изображений и можно получить текст из PDF файла. Максимальный размер исходного файла 6 Мб., обработка занимает всего несколько секунд.

Всеми этими сервисами вы можете попробовать воспользоваться прямо сейчас, распознать текст у вас точно получится, хотя бы один из инструментов справится со своей задачей.
Если будете выделять текст с фотографий, старайтесь загружать качественные снимки, иначе сервисы не справятся с обработкой.
Как вы понимаете, перепечатывать книги, курсовые и прочую текстовую информацию совсем не обязательно. Сканируете необходимые страницы и обрабатываете их специальными сайтами, получив текстовый формат, его можно переносить в обычный Word, блокнот, Power Point или даже отправить сообщением в интернете.
Вам также будет интересно:
— Создание успешного контекстного объявления
— Ударные слова и ритм текста
— Как повысить уникальность текста?
OCRONLINE
– онлайн сервис, который позволяет распознать текст с картинки (разрешения JPG, TIFF, PNG, GIF), а также PDF-файлов. Сервис поддерживает высокую точность распознавания текста на нескольких языках, и многостраничные документы сложной верстки. OCROnline имеет улучшенный многоязычную поддержку и возможность обработки документов на 153 языках мира. И при всем этом сервис бесплатный. На выходе можно получить файлы в формате TXT,DOC, RTF или PDF, что очень даже не плохо.
Есть и ограничения:
Обязательная регистрация в сервисе (займет не более 1 минуты);
- Каждый пользователь получает 5 страниц бесплатно при регистрации. Но каждый понедельник лимит обнуляется и опять в запасе 5 страниц;
- Размер файла не более 10 Мб;
- Файлы хранятся 24 часа, после чего удаляются (так что после распознания, сразу скачивайте на свой компьютер).
Для того чтобы преобразовать картинку в текст, необходимо для начала зарегистрироваться. После получаем доступ к аккаунту сервиса OCROnline и начинаем выполнять следующие действия:
Могу отметить, что для бесплатного сервиса очень неплохо распознает текст, так что пользуйтесь.
NEWOCR.COM
— это бесплатный онлайн сервис OCR (оптического распознавания символов), может анализировать текст в любом файле изображения, которое вы загружаете, и затем конвертировать картинку в текст, который можно легко редактировать на вашем компьютере.
Особенности:
- Неограниченная загрузка файлов;
- Регистрация не требуется;
- Сохраняет данные в безопасности (все загруженные пользователем файлы удаляются с сервера);
- Поддержка до 75 языков и шрифтов;
- Поддержка многоколоночный документ;
- Картинки можно вращать: по часовой стрелке/против часовой стрелки на 90°, 180°;
- Различные варианты отображения и обработки полученного текста
- Можно продолжать редактирование документа в Google Docs
- Перевод с помощью Google Translate или Bing Translator
- Копировать в буфер обмена
- Поддерживает плохо отсканированных и сфотографированных документов;
- Поддерживает изображения с низким разрешением.
Входные форматы файлов:
- Изображения: JPEG, JFIF, PNG, GIF, BMP, PBM, PGM, PPM, PCX;
- Сжатые файлы: Unix compress, bzip2, bzip, gzip;
- Многостраничных документов: TIFF, PDF, DjVu;
- Документы:DOCX, ODT файлов с изображениями;
- Несколько изображений в ZIP-архиве;
Форматы выходных файлов
- Обычный текст (TXT);
- Microsoft Word (DOC);
- Adobe Acrobat (PDF);
Для того, чтобы распознать текст с картинки: загружаем файл (кнопка Обзор) или указывает ссылку на него (File URL). После этого нажимаем на кнопку Preview. На Следующей странице добавляем язык (по умолчанию стоит русский и английский), указываем поворот входного файла (картинки), если в тексте есть колонки, то ставим галочку (Page layout analysis — split multi-column text into columns) и нажимаем на кнопку OCR. По окончанию получаем распознанный текст, который можно скачать, нажав на кнопку Download.
Суть процедуры
О каком же процессе в данном случае вообще идет речь? Обработка картинки или фото для того, чтобы текст, запечатленный на ней, автоматически был переведен в текстовый формат.
Тоесть, технически процесс происходит следующим образом: пользователь загружает картинку на сервер, либо переносит ее в программу, софт обрабатывает изображение, используя особые алгоритмы, и выдает в виде файла или в окне программы сфотографированный текст в печатном виде.
В настоящее время разработано достаточно много таких разнообразных программ.
Они отличаются по функционалу совсем незначительно, но могут существенно отличаться по качеству обработки.
Некоторые программы допускают достаточно много ошибок в распознаваемом тексте, тогда как другие – распознают все практически идеально.
Качество распознавания зависит от изначального качества фото, но при прочих равных условиях большую роль играют алгоритмы работу и обширность базы используемого приложения или онлайн-сервиса.

Важно! Такие программы могут быть представлены самостоятельным инсталлируемым софтом, простыми мобильными утилитами, способными работать с карты памяти, онлайн-сервиса, приложениями для смартфона и/или планшета. Распространяется такой софт платно или бесплатно, некоторые платные программы имеют ограниченные демо-версии.
Особенности
Каждая программа способна работать только с теми символами, которые были занесены в ее базу, только их она распознает.
В программу может быть внесено несколько алфавитов, как уже писалось выше, поэтому, при выборе подходящего софта проверьте, что бы он работал с языком, на котором напечатан текст на вашей картинке.
Если речь идет о не слишком популярных и визуально нестандартных языках, то найти подходящий софт может быть непросто.
Чем сложнее форматирование или расположение букв на фотографии, тем сложнее программе правильно распознать текст, и тем больше будет ошибок.
Ведь иногда в таком случае неточности могут возникнуть уже на стадии определения местоположения печатных символов на картинке.
Распознавание текста, напечатанного на нестандартном языке, происходит с ошибками. Причем, часто чем сложнее этот текст, тем больше ошибок может быть, так как алгоритмы распознавания могут в этом случае работать неточно.
При определении буквы программа использует определенный «алгоритм» сравнений с ее основными чертами – расположением и размером элементов (некоторые утилиты также учитывают соседние распознанные буквы и лексическую сочетаемость).
Благодаря этой особенности, даже если небольшая часть буквы стерлась или изменена, она все еще может быть распознана.
Единственный минус данного способа в том, что когда букву не удается распознать, задействуются все алфавиты из базы для определения, и в результате может быть обнаружено больше сходств с буквой, например, английского алфавита, хотя текст напечатан на русском.
Перед началом процесса распознавания, обратите внимание на качество фото. Лучше всего определяется текст с отсканированных изображений документов, скриншотов
Лучше всего определяется текст с отсканированных изображений документов, скриншотов.
Более или менее нормально может быть определен и сфотографированный на камеру текст.
Хуже всего распознаются материалы с фото плохого качества, сделанного под углом, особенно если имеет место сложное форматирование.
Художественные шрифты не распознаются.

Текущее состояние технологии оптического распознавания текста
Точное распознавание латинских символов в печатном тексте в настоящее время возможно, только если доступны чёткие изображения, такие, как сканированные печатные документы. Точность при такой постановке задачи превышает 99 %, абсолютная точность может быть достигнута только путём последующего редактирования человеком. Проблемы распознавания рукописного «печатного» и стандартного рукописного текста, а также печатных текстов других форматов (особенно с очень большим числом символов) в настоящее время являются предметом активных исследований.
Точность работы методов может быть измерена несколькими способами и поэтому может сильно варьироваться. К примеру, если встречается специализированное слово, не используемое для соответствующего программного обеспечения, при поиске несуществующих слов, ошибка может увеличиться.
Распознавание символов онлайн иногда путают с оптическим распознаванием символов. Последний — это офлайн-метод, работающий со статической формой представления текста, в то время как онлайн-распознавание символов учитывает движения во время письма. Например, в онлайн-распознавании, использующем PenPoint OS или планшетный ПК, можно определить, с какой стороны пишется строка: справа налево или слева направо.
Онлайн-системы для распознавания рукописного текста «на лету» в последнее время стали широко известны в качестве коммерческих продуктов. Алгоритмы таких устройств используют тот факт, что порядок, скорость и направление отдельных участков линий ввода известны. Кроме того, пользователь научится использовать только конкретные формы письма. Эти методы не могут быть использованы в программном обеспечении, которое использует сканированные бумажные документы, поэтому проблема распознавания рукописного «печатного» текста по-прежнему остаётся открытой. На изображениях с рукописным «печатным» текстом без артефактов может быть достигнута точность в 80 % — 90 %, но с такой точностью изображение будет преобразовано с десятками ошибок на странице. Такая технология может быть полезна лишь в очень ограниченном числе приложений.
Ещё одной широко исследуемой задачей является распознавание рукописного текста. В данное время достигнутая точность даже ниже, чем для рукописного «печатного» текста. Более высокие показатели могут быть достигнуты только с использованием контекстной и грамматической информации. Например, в ходе распознания искать целые слова в словаре легче, чем пытаться выявить отдельные знаки из текста. Знание грамматики языка может также помочь определить, является ли слово глаголом или существительным. Формы отдельных рукописных символов иногда могут не содержать достаточно информации, чтобы точно (более 98 %) распознать весь рукописный текст.
Для решения более сложных задач в области распознавания используются, как правило, интеллектуальные системы распознавания, такие, как искусственные нейронные сети.
Для калибровки систем распознавания текста создана стандартная база данных MNIST, состоящая из изображений рукописных цифр.
Краткое описание плагина Copyfish
С помощью этого плагина, можно в пару щелчков мыши скопировать текст с любой картинки, PDF и даже видео. Также это расширение может служить как переводчик. Есть конечно и другие плагины для перевода, но они не могут читать текст с картинки и видео.
Преимущества:
- Copyfish — бесплатный плагин;
- Для извлечения текста, не нужно пользоваться отдельным сервисом или программой;
- Сканировать можно не только изображения в Интернете, но и на компьютере;
- Для быстрой работы с плагином, предусмотрены горячие клавиши.
Работа с расширением
Установите расширений в браузер. В верхнем правом углу должен появиться значок Copyfish. Далее, кликните по этой иконке, а затем выделите с помощью мышки текст в рамочку.
Отпустив клавишу, Вы получите через несколько секунд оригинальный текст и его перевод, если функция перевода включена в настройках.
Клавиши:
- Redo OCR – выполнить повторное распознавание;
- Recapture — выполнить захват снова;
- Re-translate – выполнить перевод еще раз;
- Copy to clipboard – скопировать в буфер обмена.
Подобным образом можно считывать текст и с локальных файлов, которые находятся на компьютере, будь-то PDF, изображение или видео. Для этого нужно перетащить файл с ПК в окно браузера Chrome, а затем выполнить действия описанные выше. В Mozilla эта возможность пока недоступна.
Для перевода субтитров в видео, можно воспользоваться клавишей «Recapture», которая выполняет повторный захват. Также читайте, как переводить видео с английского языка на русский с помощью программы Virtual Audio Cable и блокнота Speech Pad.
Настройки расширения Copyfish
Кликните правой клавишей мыши по иконке в правом верхнем углу браузера, а затем выберите «Параметры». Настройки я разделил на три блока:
- Input Language (OCR Language): выбрать язык, который нужно перевести по умолчанию.
- Input Language Quickselect: можно назначить до трех языков для быстрого перевода.
- Translate to: выбрать язык, на который будет выполнен перевод.
- Show Text Overlay: показать наложение текста. Так можно понять, какие слова были распознаны, а какие нет.
Здесь можно видеть, что был распознан весь текст , кроме слова «coloured», в нем не была распознана буква «d».
- Translate after OCR: переводить текст после распознавания.
- Text Box Font Size: задать размер шрифта;
- Support popup dictionaries: поддержка всплывающих словарей.
Быстрые клавиши
- Open grabbing screen — открыть захват экрана CTR+SHIFT+O;
- Close panel – закрыть панель CTR+SHIFT+ X;
- Copy text – скопировать текст CTR+SHIFT+ С.
Можно воспользоваться и бесплатным сервисом для распознавания текста онлайн с картинки, PDF или видео.
Преобразование графического файла
- Откройте страницу drive.google.com на компьютере.
- Нажмите на нужный файл правой кнопкой мыши.
- Выберите Открыть с помощью Google Документы.
- Графический файл будет преобразован в документ Google. При этом некоторые параметры форматирования могут не сохраниться.
- Тип, начертание (полужирный, курсив) и размер шрифта, а также переносы строк обычно сохраняются.
- Списки, таблицы, столбцы, обычные и концевые сноски, скорее всего, не сохранятся.
Поддерживаемые языки
- Ачехский
- Ачоли
- Адангме
- Африкаанс
- Акан
- Албанский
- Алгонкинский
- Амхарский
- Древнегреческий
- Арабский (современный стандартный)
- Арауканский/мапуче
- Армянский
- Ассамский
- Астурийский
- Атабаскский
- Аймара
- Азербайджанский
- Азербайджанский (дореформенная кириллица)
- Балийский
- Бамбара
- Банту
- Башкирский
- Баскский
- Батак
- Белорусский
- Бемба
- Бенгальский
- Бикольский
- Бислама
- Боснийский
- Бретонский
- Болгарский
- Бирманский
- Каталанский
- Себуанский
- Чеченский
- Чероки
- Китайский (мандаринский, Гонконг)
- Китайский (упрощенный, мандаринский)
- Китайский (традиционный, мандаринский)
- Чоктавский
- Чувашский
- Кри
- Крикский
- Крымско-татарский
- Хорватский
- Чешский
- Дакота
- Датский
- Дивехи
- Дуала
- Нидерландский
- Дзонг-кэ
- Эфик
- Английский (США)
- Английский (Великобритания)
- Эсперанто
- Эстонский
- Эве
- Фарерский
- Фиджийский
- Филиппинский
- Финский
- Фон
- Французский (Канада)
- Французский (Европа)
- Фула
- Га
- Галисийский
- Ганда
- Гайо
- Грузинский
- Немецкий
- Кирибати
- Готский
- Греческий
- Гуарани
- Гуджарати
- Гаитянский креольский
- Хауса
- Гавайский
- Иврит
- Гереро
- Хилигайнон
Хинди - Венгерский
- Ибанский
- Исландский
- Игбо
- Илоканский
- Индонезийский
- Ирландский
- Итальянский
- Японский
- Яванский
- Кабильский
- Качинский
- Гренландский
- Камба
- Каннада
- Канури
- Каракалпакский
- Казахский
- Кхаси
- Кхмерский
- Кикуйю
- Киньярванда
- Киргизский
- Коми
- Конго
- Корейский
- Косяэ
- Куаньяма
- Лаосский
- Латынь
- Латышский
- Лингала
- Литовский
- Нижненемецкий
- Лози
- Луба-катанга
- Луо
- Македонский
- Мадурский
- Малагасийский
- Малайский
- Малаялам
- Мальтийский
- Мандинго
- Мэнский
- Маори
- Маратхи
- Маршалльский
- Менде
- Среднеанглийский
- Средневерхненемецкий
- Минангкабау
- Могаукский
- Монго
- Монгольский
- Науатль
- Навахо
- Ндонга
- Непальский
- Ниуэ
- Северный ндебеле
- Северный сото
- Норвежский (букмол)
- Ньянджа
- Ньянколе
- Тонга (Ньяса)
- Нзима
- Окситанский
- Оджибве
- Древнеанглийский
- Старофранцузский
- Древневерхненемецкий
- Древнескандинавский
- Старопровансальский
- Ория
- Осетинский
- Пампанга
- Пангасинанский
- Папьяменто
- Пушту
- Персидский
- Польский
- Португальский (Бразилия)
- Португальский (Европа)
- Панджаби (гурмукхи)
- Кечуа
- Румынский
- Романшский
- Цыганский
- Рунди
- Русский
- Русский (дореформенный)
- Якутский
- Самоанский
- Санго
- Санскрит
- Шотландский
- Шотландский (гэльский)
- Сербский (кириллица)
- Сербский (латиница)
- Шона
- Сингальский
- Словацкий
- Словенский
- Сонгай
- Южный сото
- Испанский (Европа)
- Испанский (Латинская Америка)
- Сунданский
- Суахили
- Свати
- Шведский
- Таитянский
- Таджикский
- Тамильский
- Татарский
- Телугу
- Темне
- Тайский
- Тибетский
- Тигринья
- Тонганский
- Тсонга
- Тсвана
- Турецкий
- Туркменский
- Удмуртский
- Урду
- Узбекский
- Узбекский (дореформенная кириллица)
- Венда
- Вьетнамский
- Водский
- Валлийский
- Фризский (западный диалект)
- Волоф
- Коса
- Идиш
- Йоруба
- Сапотекский
- Зулу
Onlineocr.net
Поиск по картинке в Гугл (Google) Как правильно пользоваться сервисом? +Отзывы

№7. Onlineocr.net
Простой и ненавязчивый, но в то же время вполне современный дизайн этого сайта делает работу с ним весьма приятной. А вот с характеристиками дела обстоят не очень хорошо. Сервис поддерживает крайне малое количество форматов изображений.
А форматов для сохранения готового текста и вовсе всего три штуки. Зато сервис совершенно бесплатен и работает с довольно высокой скоростью. Не радует только максимальный размер загружаемого файла – всего 15 Мб. Придется повторять процедуру много раз.
Преимущества:
- превосходный дизайн без лишних элементов
- очень высокая скорость работы
- простота в использовании
- русский язык в интерфейсе
- используется защищенное соединение
- присутствует мощный алгоритм распознавания
- отличная оптимизация сайта
Недостатки:
- очень мало поддерживаемых текстовых форматов (3)
- не хватает некоторых языков распознавания
- смешной лимит на максимальный размер загружаемого файла
Онлайн-сервисы
FineReader Online
Признанный лидер рынка, отлично распознающий текст из файлов разного формата. Единственный минус – сервис этот платный. Бесплатно в месяц можно распознать не более 5 страниц. Если вы постоянно нуждаетесь в переводе из JPG в Word – покупайте пакет страниц.
Для разового же распознавания сервис подходит идеально. Поэтому если нужно перевести в Word меньше 5 страниц, воспользуйтесь приведенной ниже инструкцией:
- Перейдите на сайт https://finereaderonline.com/ru-ru. Создайте учетную запись (простая регистрация – e-mail и пароль).
- Нажмите кнопку «Распознать».
- Загрузите файл.
- Выберите язык (можно выбрать одновременно 3 языка).
- Укажите формат сохраняемого документа.
- Нажмите «Распознать».
После завершения конвертации откроется страница с распознанным текстом. Чтобы сохранить документ, просто нажмите на него.
OCR Convert
Если вы не хотите регистрироваться и вам не хватает тех возможностей, что бесплатно предоставляет сервис FineReader Online, то попробуйте альтернативные варианты. Например, используйте OCR Convert:
- Загрузите файл.
- Выберите язык.
- Укажите, что вы не робот.
- Нажмите «Process».
Из недостатков сервиса можно выделить ограниченный выбор форматов на выходе – текст переводится только в TXT. Еще один минус – слабое, по сравнению с FineReader, распознавание.
Ограничение на вес стандартное – 5 Мб. Без регистрации в час можно распознать 15 изображений. Если заведете учетную запись, ограничение снимается.
i2OCR
Еще один удобный сервис, поддерживающий более 60 языков и все основные форматы изображений. Главное отличие от предыдущих конвертеров – наличие возможности загрузить снимок из URL.
Порядок работы тот же: указываете язык, выбираете файл, вводите капчу и нажимаете «Extract Text».
Есть и другие подобные сервисы – Newocr, Free-OCR и другие OCR, позволяющие распознать текст с изображений. Однако нужно понимать, что машинный алгоритм не является безошибочным. Поэтому внимательно вычитывайте тексты после конвертации, чтобы не попасть в неловкую ситуацию.
https://youtube.com/watch?v=swFllPGrPNA
Применение методов распознавания образов в медицине
Методы Р. о. нашли практическое применение в медицине, многие узловые проблемы к-рой связаны с вопросами классификации и прогнозирования. К основным задачам медицины, решаемым с помощью методов распознавания, относятся следующие.
1. Задачи медицинской дифференциальной диагностики. Для многих групп заболеваний со сходной симптоматикой удается построить решающие правила, с помощью которых диагностика проводится с высокой точностью. 2. Прогноз осложнений при лечении. Для той или иной схемы лечения строятся решающие правила, позволяющие для каждого больного определить особенность протекания лечения (лечение пройдет без осложнений, с осложнением типа 1, типа 2 и т. д.). 3. Прогноз отдаленных результатов лечения. Для каждого больного при заданной схеме лечения прогнозируется один из возможных исходов лечения. В случае нескольких альтернативных схем лечения на основе результатов прогноза для каждой из них можно выбрать для данного больного прогностически наиболее благоприятную схему. 4. Выделение групп людей повышенного риска. Строится правило, с помощью к-рого по индивидуальным особенностям человека, характерным для него привычкам, особенностям среды, в к-рой он проживает, прогнозируется возможность заболевания конкретной болезнью. Лица с неблагоприятным прогнозом объединяются в группу риска. Оказалось, что в выделенной группе риска концентрация людей с определенной патологией в десятки раз превосходит концентрацию аналогичных больных в контрольной группе.
Большие работы по применению методов Р. о. проводятся в теоретической медицине. Напр., создаются комплексные тесты, позволяющие судить о наличии конкретного заболевания не по одному специфическому тесту, а по набору неспецифических тестов. Методами Р. о. может быть решена одна из наиболее важных задач — задача выбора целесообразного для клин, испытаний препарата. Так, в мировой онкологической клин, практике апробировано менее 100 противоопухолевых препаратов, в то же время в поисках эффективных лекарств синтезируются сотни новых противоопухолевых средств. Эти новые лекарственные средства проверяются на различных моделях опухолей (в т. ч. и на опухолях животных). Однако эффективность препарата на моделях еще не гарантирует его эффективности в клинике. Проблема состоит в том, чтобы, имея информацию о клин. активности апробированных препаратов и информацию об активности этих же препаратов на различных моделях, выбрать по результатам испытания на моделях среди вновь синтезированных препаратов наиболее активный в клинике.
Развитие методов Р. о. на практике связано с созданием автоматизированных систем управления (см.), и в частности таких систем, которые позволяют накапливать большое количество информации — банки данных. Используя эти банки, можно в режиме диалога с машиной строить решающие правила, рассчитанные на имеющуюся в данный момент информацию, оценивать точность проводимой с помощью построенного правила классификации, определять необходимые дополнительные элементы описания ситуации для увеличения точности классификации и т. д. Создание таких систем позволит использовать ЭВМ на всех уровнях принятия альтернативных решений.
См. также Математические методы в медицине, Прогнозирование, Решающее правило, Электронная вычислительная машина.
Библиография: Вапник В. Н. Восстановление зависимостей по эмпирическим данным, М., 1979; Вапник В. Н. и Червоненкис А. Я. Теория распознавания образов, М., 1974; Вапник В. H., Глазкова Т. Г. и Миллер И. Ранжирование препаратов для клинических испытаний, в кн.: Эксперим. оценка противоопухолевых препаратов в СССР и США, под ред. 3. П. Софьиной и др., с. 184, М., 1980; Глазкова Т. Г. и Гурарий К. Н. Применение математических методов в онкоэпидемиологических исследованиях, Эпидемиология в странах СЭВ, М., 1979; Гублер Е. В. Вычислительные методы анализа и распознавания патологических процессов, JI., 1978; Распознавание образов и медицинская диагностика, под ред. Ю. И. Неймарка, М., 1972.
В. Н. Вапник.