Системы распознавания текста и программы-переводчики
Содержание:
- Обзор популярных продуктов
- Угадай, что на картинке
- ФОРМУЛА ИЗОБРЕТЕНИЯ
- Возможности технологии
- Основные сложности
- Прогнозы аналитиков
- Фейс-хакинг активизм
- Программы оптического распознавания символов
- Как работает распознавание лиц
- Как работают камеры
- ABBYY FineReader Рукопись
- САРР что это такое
- Личные данные
- Итог
Обзор популярных продуктов
Face -Интеллект от компании «House Control», которая занимается устройством и обслуживанием систем безопасности различного уровня от промышленных и общественных объектов до офиса и дома. Программа работает на надежном алгоритме компании «Cognitec» и имеет высокий коэффициент распознания. Стоимость от 2250$ для базы в 10 человек до 5100 $ для базы в 200 человек.
FaceDetector – от компании Синезис, разработчика интеллектуальных систем видеонаблюдения и программ видеоаналитики для бизнеса. Программа имеет широкие функциональные возможности особенно в построении разнообразных отчетов. По ним можно определить какие посетители (пол, возраст) наиболее часто останавливались возле определенных прилавков, стеллажей, отделов. Из основных преимуществ программы нужно отметить возможность идентификации при довольно больших углах поворота лиц до 90°в горизонтальной плоскости и до 30° в вертикальной. При попытке прикрыть лицо (в том числе и маской) срабатывает детектор предупреждения.
FaceControl – от компании Вокорд, специализирующийся на разработке систем видеонаблюдения с уникальными характеристиками. Программа может распознать пол и возраст, подсчитать частоту посещения, сгенерировать отчеты. Производит аналитический поиск в архиве.
Видеонаблюдение с функцией распознания лиц будет полезно не только системам безопасности, но и в бизнесе, для осуществления анализа посетителей.
Угадай, что на картинке
Как будет развиваться компьютерное зрение?
Александр Ханин: Есть большая группа задач, именуемых visual question answering: вы показываете компьютеру картинку, и он должен понять, что там изображено. Это очень сложно: если просто учить распознавать объекты по отдельности, ничего не получится — надо понимать контекст и взаимосвязь объектов.
Другая похожая задача — распознавание действий человека, они ведь тоже определяются во многом по контексту. Например, если человек поднял руку, что это значит? Он указывает дорогу или собирается кого-то ударить? Вот сидим, думаем.
То есть вы хотите научить машины распознавать образы, смысл которых зависит от контекста?
Александр Ханин: Научить интерпретировать контекст и таким образом распознавать картинки, действия, сцены.
ФОРМУЛА ИЗОБРЕТЕНИЯ
1. Система распознавания объектов и слежения за ними, содержащая по меньшей мере один матричный датчик, причем указанный или каждый матричный датчик предназначен для выполнения функций датчика первого типа, обеспечивающего возможность обнаружения присутствия объекта в рабочей зоне датчика и определения положения этого объекта, и датчика второго типа, обеспечивающего возможность использования этого положения объекта, определенного датчиком первого типа, для идентификации и распознавания объекта, и возможность фокусирования или работы с более высокой разрешающей способностью, чем датчик первого типа.
2. Система по п. 1, отличающаяся тем, что присутствие объекта, определяемое датчиком первого типа, может быть обнаружено по изменениям в контрастных границах или по изменениям в картине изображения или по перемещениям, и тем самым система может обнаруживать объекты, которые движутся в рабочей зоне датчика.
3. Система по п. 1, отличающаяся тем, что датчик второго типа выполнен с возможностью подсчёта или регистрации присутствия объекта, если он является объектом некоторого выбранного типа.
4. Система по п. 1, отличающаяся тем, что матричный датчик выполнен с возможностью использования части электромагнитного спектра, выбранной из радиолокационного, микроволнового, радиочастотного, инфракрасного, миллиметрового и оптического диапазонов, либо с возможностью использования звуковой локации или другой системы обнаружения.
5. Система по п. 1, отличающаяся тем, что датчики первого и второго типа выполнены в виде единого телевизионного датчика, наблюдаемое которым изображение обрабатывается двумя различными путями, при использовании первого из которых наблюдаемое изображение может оцифровываться и последовательные изображения могут анализироваться для обнаружения изменений в последовательных кадрах оцифрованного изображения, которые указывают на присутствие объекта, а при использовании второго то же самое оцифрованное изображение в определенной области рабочей зоны датчика может затем анализироваться более детально.
6. Система по п. 5, отличающаяся тем, что датчик второго типа выполнен с возможностью использования последующих или предыдущих кадров для улучшения распознавания или результата в отношении объекта, представляющего интерес.
7. Система по п. 1, отличающаяся тем, что для определения и идентификации объектов используется одна или несколько таких характеристик, как масса, высота, форма, контраст, яркость, цвет, узоры, скорость, тепло, отражательная способность, сигнатура.
8. Система по п. 1, отличающаяся тем, что она дополнительно содержит машину для слежения, выполненную с возможностью слежения за определенным объектом.
9. Система по п. 1, отличающаяся тем, что она содержит несколько матричных датчиков и несколько рабочих зон датчиков.
10. Система по п. 9, отличающаяся тем, что она включает средства взаимодействия между матричными датчиками для передачи слежения за выбранным объектом из одной рабочей зоны в соседнюю рабочую зону.
11. Система по п. 10, отличающаяся тем, что средства взаимодействия между матричными датчиками содержат средства передачи информации на следующие датчики или другие устройства третьих лиц, требующие такой информации для осуществления, когда это необходимо, запрограммированных действий без человеческого вмешательства.
12. Система по п. 1, отличающаяся тем, что она содержит средства учета угла, под которым объект находится относительно матричного датчика, или учета смещения объектов относительно центра в пределах двумерной или трехмерной зоны.
13. Система по п. 1, отличающаяся тем, что указанный или каждый матричный датчик установлен, по существу, над своей рабочей зоной.
14. Система по п. 1, отличающаяся тем, что указанный или каждый матричный датчик установлен сбоку от своей рабочей зоны.
15. Система по п. 1, отличающаяся тем, что она используется для подсчета людей в супермаркетах или других подобных местах или для транспорта, перемещающегося вдоль дороги, для охранного наблюдения и контроля и для определения законов или тенденций кажущихся случайными перемещений в течение некоторого времени, например, при передвижении людей по магазину или выставочной площади.
16. Система по п. 1, отличающаяся тем, что она используется на движущемся транспортном средстве для обнаружения объектов, которые по сравнению с транспортным средством относительно неподвижны.
Возможности технологии
Прямо сейчас по всему миру разработчики массово внедряют технологию распознавания лица в жизнь простых людей. К примеру, только в Москве такой метод верификации связан со 150 000 камер видеонаблюдения. Они установлены на улицах и являются частью государственной программы по борьбе с нарушителями ПДД и хулиганами.
В конце 2018 года в Китае заработал проект Smart Campus, который позволяет в онлайн-режиме наблюдать за присутствием детей на уроках. Если система определяет, что ребенка нет в кадре на протяжении 15 минут, на телефон учителя и родителей отправляется соответствующее сообщение.

Внедрение проекта Smart Campus
Возможности технологии практически безграничны. С её помощью можно улучшить систему безопасности пользователей банков, ловить опасных преступников, защищать свои гаджеты от любопытных друзей или воров и многое другое.
Основные сложности
лавная проблема, возникающая
при разработке САРР, заключается в вариативном произношении одного и того же
слова как разными людьми, так и одним и тем же человеком в различных ситуациях.
Человека это не смутит, а вот компьютер — может. Кроме того, на входящий сигнал
влияют многочисленные факторы, такие как окружающий шум, отражение, эхо и помехи
в канале. Осложняется это и тем, что шум и искажения заранее неизвестны, то
есть система не может быть подстроена под них до начала работы.
Однако более чем полувековая работа над различными САРР дала свои плоды. Практически
любая современная система может работать в нескольких режимах. Во-первых, она
может быть зависимой или независимой от диктора. Зависимая от диктора система
требует специального обучения под конкретного пользователя, чтобы точно распознавать
то, что он говорит. Для обучения системы пользователю надо произнести несколько
определенных слов или фраз, которые система проанализирует и запомнит результаты.
Этот режим обычно используется в системах диктовки, когда с системой работает
один пользователь.
Дикторонезависимая система может быть использована любым пользователем без обучающей
процедуры. Этот режим обычно применяется там, где процедура обучения невозможна,
например в телефонных приложениях. Очевидно, что точность распознавания дикторозависимой
системы выше, чем у дикторонезависимой. Однако независимая от диктора система
удобнее в использовании, например она может работать с неограниченным кругом
пользователей и не требует обучения.
Во-вторых, системы делятся на работающие только с изолированными командами и
на способные распознавать связную речь. Распознавание речи является значительно
более сложной задачей, чем распознавание отдельно произносимых слов. Например,
при переходе от распознавания изолированных слов к распознаванию речи при словаре
в 1000 слов процент ошибок увеличивается с 3,1 до 8,7, кроме того, для обработки
речи требуется в три раза больше времени.
Режим изолированного произнесения команд наиболее простой и наименее ресурсоемкий.
При работе в этом режиме после каждого слова пользователь делает паузу, то есть
четко обозначает границы слов. Системе не требуется самой искать начало и конец
слова в фразе. Затем система сравнивает распознанное слово с образцами в словаре,
и наиболее вероятная модель принимается системой. Этот тип распознавания широко
используется в телефонии вместо обычных DTMF-методов
.
Режим слитного произнесения более натурален и близок пользователю. При этом
предполагается, что система сама различит границы слов во фразе. Однако этот
режим требует гораздо больше системных ресурсов и памяти, а точность распознавания
ниже, чем в предыдущем режиме. Почему это так? Причин несколько. Во-первых,
при слитной речи произнесение слов менее аккуратно, чем в «режиме PIN-кода»,
то есть когда каждое слово произносится отдельно. Во-вторых, скорость речи даже
у одного человека разная. Он может задуматься, засомневаться, забыть слово.
В разговорной речи часто встречаются слова-паразиты: «ну», «а», «вот». Кроме
того, границы слов часто смазываются, произносятся нечетко, что затрудняет работу
системы.
Дополнительные вариации в речи возникают также из-за произвольных интонаций,
ударений, нестрогой структуры фраз, пауз, повторов и т.д.
На стыке слитного и раздельного произнесения слов возник режим поиска ключевых
слов. В этом режиме САРР находит заранее определенное слово или группу слов
в общем потоке речи. Где это может быть использовано? Например, в подслушивающих
устройствах, которые включаются и начинают запись при появлении в речи определенных
слов, или в электронных справочных. Получив запрос в произвольной форме, система
выделяет смысловые слова и, распознав их, выдает необходимую информацию.
Размер используемого словаря — важная составляющая САРР. Очевидно, что чем
больше словарь, тем выше вероятность того, что система ошибется. Во многих современных
системах есть возможность или дополнять словари по мере необходимости новыми
словами, или подгружать новые словари. Обычный уровень ошибок для дикторонезависимой
системы с изолированным произнесением команд — около 1% для словаря в 100 слов,
3% — для словаря в 600 слов и 10% — для словаря в 8000 слов.
Прогнозы аналитиков
егодня технологии распознавания
речи считаются одними из наиболее перспективных в мире. Так, по прогнозам американской
исследовательской компании Cahners In-Stat, мировой рынок ПО распознавания речи
к 2005 году увеличится с 200 млн. до 2,7 млрд. долл. По мнению же фирмы Datamonitor,
объем рынка голосовых технологий будет расти в среднем на 43% в год: с 650 млн.
долл. в 2000 году до 5,6 млрд. долл. в 2006-м (рис. 1).
Эксперты, сотрудничающие с медиакорпорацией CNN, отнесли распознавание речи
к одной из восьми наиболее перспективных технологий нынешнего года. А аналитики
из IDC заявляют, что к 2005 году распознавание речи вообще вытеснит с рынка
все остальные речевые технологии (рис. 2).
Фейс-хакинг активизм
Механика учит, что каждое действие создает противодействие, и быстрое развитие систем наблюдения и идентификации личности не исключение. Сегодня нейросети позволяют сопоставить случайную смазанную фотографию с улицы со снимками, загруженными в аккаунты социальных сетей и за секунды выяснить личность прохожего. В то же время художники, активисты и специалисты по машинному зрению создают средства, способные вернуть людям приватность, личное пространство, которое сокращается с такой головокружительной скоростью.
Помешать идентификации можно на разных этапах работы алгоритмов. Как правило, атакам подвергаются первые шаги процесса распознавания — обнаружение фигур и лиц на изображении. Как военный камуфляж обманывает наше зрение, скрывая объект, нарушая его геометрические пропорции и силуэт, так и машинное зрение стараются запутать цветными контрастными пятнами, которые искажают важные для него параметры: овал лица, расположение глаз, рта и т. д. По счастью, компьютерное зрение пока не столь совершенно, как наше, что оставляет большую свободу в выборе расцветок и форм такого «камуфляжа».

Розовые и фиолетовые, желтые и синие тона доминируют в линейке одежды HyperFace, первые образцы которой дизайнер Адам Харви и стартап Hyphen Labs представили в январе 2017 года. Пиксельные паттерны предоставляют машинному зрению идеальную — с ее точки зрения — картинку человеческого лица, на которую компьютер ловится, как на ложную цель. Несколько месяцев спустя московский программист Григорий Бакунов и его коллеги даже разработали специальное приложение, которое генерирует варианты макияжа, мешающего работе систем идентификации. И хотя авторы, подумав, решили не выкладывать программу в открытый доступ, тот же Адам Харви предлагает несколько готовых вариантов.

Человек в маске или со странным гримом на лице, может, и будет незаметен для компьютерных систем, но другие люди наверняка обратят на него внимание. Однако появляются способы сделать и наоборот
Ведь с точки зрения нейросети изображение не содержит образов в обычном для нас понимании; для нее картинка — это набор чисел и коэффициентов. Поэтому совершенно различные предметы могут выглядеть для нее чем-то вполне сходным. Зная эти нюансы работы ИИ, можно вести более тонкую атаку и подправлять изображение лишь слегка — так, что человеку перемены будут почти незаметны, зато машинное зрение обманется полностью. В ноябре 2017 года исследователи показали, как небольшие изменения в окраске черепахи или бейсбольного мяча заставляют систему Google InceptionV3 уверенно видеть вместо них ружье или чашку эспрессо. А Махмуд Шариф и его коллеги из Университета Карнеги — Меллон спроектировали пятнистый узор для оправы очков: на восприятие лица окружающими он почти не влияет, а вот компьютерная идентификация средствами Face++ уверенно путает его с лицом человека, «под которого» спроектирован паттерн на оправе.
Статья «На лице написано» опубликована в журнале «Популярная механика»
(№12, Декабрь 2017).
Программы оптического распознавания символов
Системы оптического распознавания символов (OCR — Optical character recognition) стали неотьемлемой частью интегрированных пакетов, поддерживающих ввод в компьютер, хранение и обработку бумажных и электронных документов. Система включает в свой состав сканер для ввода информации.
Если созданное сканером изображение содержит текст и рисунки, то при помощи специальной программы оптического распознавания текста (OCR) можно:
- — отделить текст от рисунков;
- — записать этот текст в формате файла текстового процессора.
Программное обеспечение в современных системах OCR выполняет анализ форм букв и создание текстового файла, в который распознаваемый текст записывается посимвольно с последовательным формированием слов и предложений.
Существует два типа пакетов OCR: обучаемые и интеллектуальные. Первые пакеты оптического распознавания символов имели четкое разделение по типу. В последнее время наблюдается тенденция к объединению этих двух типов в одном пакете, что перекликается с попытками разработать принципиально новые алгоритмы распознавания.
Обучаемые пакеты программ OCR составляли большинство первых разработок. Такие пакеты теоретически способны обучаться распознаванию любых символов любых гарнитур. Для обучения программы конкретной гарнитуре нужно отсканировать эталонное изображение с последующим обучением каждому конкретному символу. Это довольно длительная процедура, однако, если данная гарнитура будет затем регулярно использоваться, стоит потратить пару часов на обучение. Программы такого типа сравнивают каждый отдельный символ страницы с символами в справочных таблицах, созданных в процессе обучения, составляя при этом текстовый файл.
Интеллектуальные пакеты OCR не нуждаются в обучении и могут интерпретировать формы символов независимо от используемой гарнитуры. Работа этих программ производит большое впечатление: документ пропускается через сканер, результат обрабатывается интеллектуальной программой OCR с выдачей текстового файла. Для страницы формата А4 вся процедура занимает немногим более одной минуты. При высокой точности это значительно быстрее ручного ввода.
FineReader — это система оптического распознавания текстов (OCR), которая преобразует полученное с помощью сканера графическое изображение (картинку) в текст (т. е. в коды букв, «понятные» системе).
Процесс ввода текстов в компьютер осуществляется в несколько этапов: сканирование; выделение блоков на изображении; распознавание; проверка ошибок; сохранение результата распознавания (передача его в другое приложение, в буфер и т. п.)
Рисунок 2. Интерфейс программы FineReader 11
Интеллектуальная система оптического распознавания символов (Optical Character Recognition, OCR) Cuneiform функционирует в среде Microsoft Windows 3.1 или более поздней версии. Система обладает следующими технологическими возможностями: поддерживает широкий спектр настольных сканеров;распознает отсканированную страницу (включая многоколонный текст и текст со сложным оформлением); позволяет сканировать и записывать изображение как TIFF, а распознавание запускать потом (при этом удобно сканировать пачку документов); может читать изображения, отсканированные другими программами, и факсы в режимах Fine и Normal;распознает буквы русского и английского алфавитов, исключая стилизованные шрифты типа готических букв; может сохранять первоначальные форматирование и табуляцию и регулировать отступы и выравнивание; не распознает рукописный текст.
Экран Сuneiform содержит четыре основные части, отмеченные на рисунке.
Рисунок 3. Интерфейс программы Сuneiform
Новая версия системы распознавания Intuitia 2.0 for Windows использует Омнифонт-технологию (распознает различные шрифты без какого бы то ни было обучения). Она обеспечивает распознавание изображений текстовых материалов из файлов в форматах TIFF, PCX, BMP, а также со всех Сканеров, поддерживающих протокол TWAIN, а также со сканеров семейства HP ScanJet (напрямую).
Система ввода и распознавания рукописных текстов PenO’Man for Windows — средство рукописного ввода, распознавания и редактирования текстов при помощи пера: имеется возможность ввода и редактирования как английского, так и русского слитно написанного текста во всех приложениях Windows; процесс ввода аналогичен обычному использованию ручки при письме слева направо, желательно аккуратным почерком и с классическим левым наклоном; редактирование уже введенного текста возможно в результате использования стандартных функций (вставке, удалению, переносу, активизации фрагментов текста и т. д.), а также простых росчерков пера.
Как работает распознавание лиц
Если вы хоть раз слышали о функции распознавания лица, то, наверняка задавались вопросом, как компьютер может «узнавать» нужного человека. Все это возможно благодаря искусственному интеллекту и машинному обучению.
Прежде чем система начнет распознавать людей с высокой точностью, её нужно этому «научить». Для этого программисты заранее тестируют на своих проектах сотни тысяч, а иногда и миллионы фотографий людей. Чем чаще система распознает лица, тем больше находит уникальных черт людей и тем выше получается точность верификации личности.
Наша уникальность — нас выдает.
Лицо каждого человека уникально. Этим и пользуется компьютер. Он определяет на лице точки (нос, лоб, глаза и так далее). Затем измеряет показатели расстояния между этими точками, глубину и еще больше двух десятков разных параметров. Таким образом, даже близнецы будут определяться как два разных человека.

Определении уникальных метрик
Процесс «считывания» лица
Большинство современных систем распознавания лиц работают с 3D-моделированием уникальных черт каждого человека. Искусственный интеллект в реальном времени наносит все показатели на виртуальное человеческое лицо, формируя его модель. Полученная информация вносится в базу данных.
Процесс распознавания работает следующим образом:
- Обнаружение лица. На этом этапе программа сканирует человека через готовый снимок или через камеру в режиме реального времени;
- Определяется лицо и его границы. Система определяет положение человека, уровень освещения;
- Измерение параметров. Программа определяет уникальные метрики и измеряет их с точностью до тысячной доли миллиметра;
- Кодирование полученных данных. Все метрики преобразовываются программой в числовую последовательность, которая позволяет компьютеру уникализировать лицо каждого человека;
- Сопоставление. Чтобы разблокировать телефон или найти человека, системе нужно сопоставить два лица. Поиск соответствия входящих данных и сохраненной информации занимает доли секунды и является максимально точным;
- Верификация или идентификация (в зависимости от целей приложения). Если распознавание лиц работает как способ разблокировать смартфон, то это называется верификацией – снимок с камеры сравнивается только с одной эталонной моделью в базе данных. Идентификация – это поиск нужного лица среди тысяч других моделей в памяти программы.
3D-моделирование внешних характеристик человека
Сегодня система распознавания работает хорошо, но во многих её реализациях наблюдается высокий процент неточностей. Успехи в совершенствовании технологии удалось сделать компании Apple. Их сканеры лица научились распознавать человека, даже если он сменил прическу, отрастил бороду или носит солнцезащитные очки во время разблокировки гаджета.
В феврале 2019 года в Рунете появился уникальный в своем роде сервис Search Face, который способен найти человека по фотографии. Поиск осуществляется среди миллионов аккаунтов социальной сети Вконтакте. Система работает практически со стопроцентной точностью, чего еще не удавалось добиться ни одному разработчику в мире. Автор сервиса остается анонимным. Единственное, что о нем известно – он из России.
Как работают камеры
Новые камеры, установленные в общественных местах и московском метрополитене, способны распознавать до 20 лиц в секунду. Алгоритм функционирования системы довольно простой: установленные камеры анализируют лицо человека, обращаясь к базам федерального розыска. Если система видит разыскиваемого человека, информация поступает дежурному полицейскому на специальный мобильный комплекс, в котором установлена программа для сравнения кадра с камер и фотографии разыскиваемого. Сразу же сотрудник полиции устанавливает причину розыска и остальные данные, а при подтверждении лица и фото происходит проверка документов. Дойдет ли дело до задержания – вопрос соответствия данных в документах данным разыскиваемого. Система также может определять подозрительные задержки в неустановленных местах и фиксировать предметы, долгое время находящиеся без движения.

За два месяца работы камер в испытательном режиме удалось задержать 6 человек, находившихся в федеральном розыске. На каких именно станциях стоят камеры сказать нельзя, эта информация содержится в тайне
Власти говорят, что особое внимание уделено станциям, расположенным рядом с местами проведения матчей чемпионата мира по футболу. Очевидно, что система была установлена не только на время проведения чемпионата, а на долгий срок
ABBYY FineReader Рукопись
Система «ABBYY FineReader Рукопись» предназначена для offline-распознавания
рукопечатных и печатных форм различного типа, включая даже те формы, которые
изначально не были предназначены для машинной обработки.
Система обладает возможностью распознавания печатных текстов на 50 языках и
рукопечатных текстов на шести языках. Благодаря различным методам удаления изображения
формы помимо традиционных цветных и растровых форм «FineReader
Рукопись» может распознавать информацию и с черно-белых форм с различными
типами разметки полей.
Программа позволяет осуществлять ввод форм различной степени сложности, включая
многостраничные формы. Масштабируемость системы делает ее пригодной для ввода
практически любых объемов информации — от простейших систем для ввода сотен
документов в день и до комплексов из десятков компьютеров для ввода сотен тысяч
документов ежедневно.
Благодаря технологии FlexiForm, реализованной в «FineReader Рукопись», возможна
обработка даже не машиночитаемых — так называемых гибких — форм.
Под задачей ввода гибких форм (FlexiForms) понимают задачу ввода одинаковых
форм, напечатанных на не строго однотипных бланках. Например, это могут быть
документы, распечатанные на различных принтерах, в различных организациях, то
есть однотипная информация на которых расположена по-разному.
В категорию гибких форм входят все формы, расположение полей в которых не зафиксировано
геометрически, что типично практически для всех финансовых документов, используемых
в России: платежных поручений, балансовых отчетов, справок о доходах, счетов,
накладных и пр.
Весьма условно алгоритм определения расположения полей на каждой конкретной
форме можно описать следующим образом: «Слева от поля есть надпись “индекс”».
Однако возможна ситуация, когда такая пометка встречается не на всех формах —
в этом случае алгоритм нужно дополнить другими «приметами» поля, например: «скорее
всего слева от поля будет вертикальная линия, а ниже поля должен быть текст
“адрес”».
Технология FlexiForm нашла свое применение во множестве различных систем по
вводу документов, включая русские платежные поручения; польские рукописные банковские
чеки; международные карточки VISA; украинские платежные поручения; литовские
библиотечные карточки; межбанковские переводы в Бельгии и многие другие.
В тех случаях, когда форма не содержит исправлений и заполнена аккуратно, программа
распознает рукописные символы, допуская менее пяти ошибок на 1000 символов,
что более чем в пять раз меньше, чем делает профессиональная машинистка.
Повышенная точность объясняется автоматическим контролем результатов распознавания
на основе проверок по словарям и базам данных. Программа автоматически проверяет
корректность результатов распознавания по базам данных, словарям, с помощью
перекрестных проверок полей, проверок сумм, форматов дат и т.д. Открытый интерфейс
позволяет пользователю создавать собственные правила автоматического контроля.
На основе FineReader API можно настраивать
интерфейс системы, запускать программу из других приложений и легко интегрировать
ее в любую другую систему обработки информации.
Используя FineReader Developer Edition, можно писать свои приложения на основе
программы «FineReader Рукопись».
FineReader распознает формы, заполненные от руки, на печатной машинке или принтере,
а также пункты (checkmarks) и штрих-коды. После распознавания FineReader выделяет
цветом все неуверенно распознанные символы и подает их на верификацию. Оператор
тратит лишь секунды, проверяя отдельные символы, вместо того чтобы тратить минуты
на полный ввод всей формы.
В России имеется целый ряд авторитетных организаций, которые уже использовали
описанную систему в своей работе. Среди них Министерство по налогам и сборам
(МНС) РФ, Пенсионный фонд РФ, Федеральный центр тестирования и ряд других организаций.
Например, обработка налоговых деклараций москвичей велась при помощи программы
«FineReader Рукопись». Это позволило МНС значительно сократить сроки и стоимость
обработки налоговых деклараций. Наверняка список клиентов, использующих данное
программное обеспечение, будет расти.
САРР что это такое
истемы автоматического распознавания
речи (САРР) — это элемент процесса обработки речи, назначение которого — обеспечить
удобный диалог между пользователем и машиной. В широком понимании речь идет
о системах, которые осуществляют фонемное
декодирование речевого акустического сигнала при произношении речевых сообщений
свободным стилем, произвольным диктором, без учета проблемной ориентации и ограничений
на объем словаря. В узком смысле САРР облегчают решение частных задач, накладывая
некоторые ограничения на требования к распознаванию естественно звучащей речи
в классическом его понимании. Таким образом, диапазон разновидностей САРР простирается
от простых автономных устройств и детских игрушек, которые способны распознавать
или синтезировать раздельно произносимые слова, цифры, города, имена и т.п.,
до суперсложных систем распознавания естественно звучащей речи и ее синтеза
для использования, например, в качестве секретаря-референта (IBM VoiceType Simply
Speaking Gold).
Являясь основной составляющей любого дружественного интерфейса между машиной
и человеком, САРР может быть встроена в различные приложения, например в системы
голосового контроля, голосового доступа к информационным ресурсам, обучения
языку с помощью компьютера, помощи недееспособным, доступа к чему-либо через
системы голосовой верификации/идентификации.
САРР весьма полезна как средство поиска и сортировки записанных аудио- и видеоданных.
Распознавание речи также используется при вводе информации, что особенно удобно,
когда глаза или руки человека заняты. САРР позволяет людям, работающим в напряженной
обстановке (врачи в больницах, рабочие на производстве, водители), применять
компьютер для получения или ввода необходимой информации.
Обычно САРР используется в таких системах, как телефонные приложения, встроенные
системы (системы набора номера, работа с карманным компьютером, управление автомобилем
и т.д.), мультимедийные приложения (системы обучения языку).
Личные данные
По заявлению разработчиков за личные данные граждан беспокоиться не стоит. Система надежна защищена и возможность взломать систему отсутствует. В ближайшее время вопросом о сборе биометрических данных пользователей займутся две стороны – российские банки и интернет провайдер «Ростелеком». Провайдер будет платить банку, который собрал первичную информацию о гражданине, 100 рублей. Банку же будет дополнительная строка дохода, что позволит проявить больший интерес для сбора информации.
Вывод.
Развитие технологий позволит обычным гражданам жить более спокойной жизнью, ведь благодаря таким техническим решениям поиски преступников не составят труда. Но вопрос безопасности личных данных граждан пока остается под вопросом. Если данные действительно не будут никуда утекать – тогда поводов для волнения не будет. Любая система подлежит взлому, но как будет с распознаванием лиц – пока остается загадкой.
Итог
Несмотря на все опасения и теории, распознавание лиц является одним из самых интересных направлений в развитии информационных технологий. Функция способна в разы повысить безопасность в наших городах, а использование сканнера лица в банковской сфере сделает невозможным кражу денег со счетов.
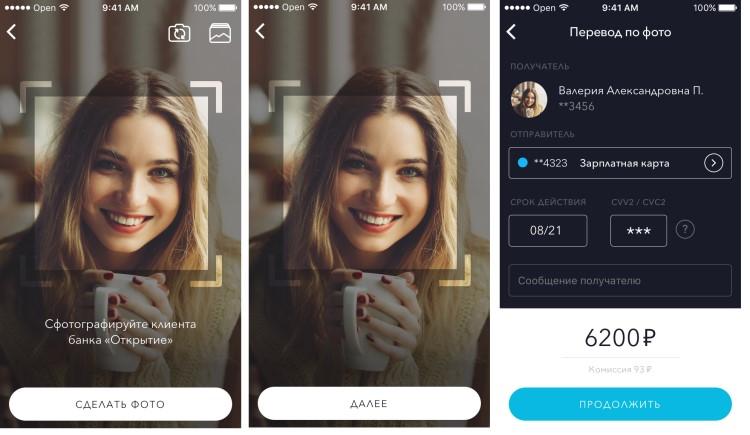
Недавно банк «Открытие» начал внедрение системы в своё мобильное приложение. Теперь пользователи могут отправлять денежные переводы по фото. Достаточно просто отсканировать снимок и приложение покажет человека, которому нужно перевести средства.
Богдан Вязовский
«Мы живем в обществе, где технологии являются очень важной частью бизнеса, нашей повседневной жизни. И все технологии начинаются с искр в чьей-то голове
Идея чего-то, чего раньше не существовало, но однажды будет изобретено, может изменить все. И эта деятельность, как правило, не очень хорошо поддерживается»